There is a lot of discussion right now about these concepts, and we decided to present actual examples to show how these terms relate to actual memory management by ESX 4.1 by conducting tests in our Proof-of-Concept lab.
Background posts
For background, we refer our readers to Duncan Epping’s blog posts, “How cool is TPS?”, where he explains Zero Pages, Large Pages, TPS and boot storm, and “Re: Large Pages.”
Server Configuration for experiments
Hardware:
- HP ProLiant DL380 G5 with dual Intel Xeon E5335 processors and 32GB memory
- HP ProLiant DL360 G6 with dual Intel Xeon E5540 processors and 32GB memory
We created 12 VMs running Windows 2003 SP2 with 4GB of configured memory. We then simultaneously powered on these 12 VMs on each ESX server provisioned with 32GB of memory to simulate a boot-storm.
Both systems are running VMware ESX 4.1 build # 260247. The reasons why we tested these two ESX servers with different Intel Xeon processors will be explained in the following section.
We monitored the memory usage during the boot storm using the ESX server memory performance chart from the vSphere client. We then exported the memory performance chart data to a Microsoft Excel worksheet. Once the data was in the Excel worksheet, we plotted the memory usage graph from the ESX memory metric data, which will be detailed later in this blog.
Processors and their impact on Zero Pages and Transparent Page Sharing – TPS
We understand that a Microsoft Windows Operating System will check how much memory it has by zeroing out pages it detects during the boot process. For Microsoft Windows VMs, this means that ESX kernel may have to allocate up to the entire configured memory to the VM as it accesses and zeroes out its memory during the boot time.
In our servers with 32GB of physical memory and 12 VMs with 4GB of configured memory, Memory Overcommitment will result if we power on these 12 VMs simultaneously and cause a boot storm. When Memory Overcommitment occurs, ESX will utilize Memory Ballooning and/or kernel Swapping (or Memory Compression in the case of vSphere 4.1) to reclaim memory.
The memory overcommit in the boot storm is largely caused by the zeroed pages, which can then be shared and reclaimed via TPS. The performance impact could thus be greatly alleviated after TPS starts to kick in. However, since TPS is based on sharing 4KB pages, TPS will not kick-in on newer processors such as Intel Nehalem Xeon 5500 processors with hardware-assisted MMU (Memory Management Unit) virtualization support, (e.g., Intel Extended Page Table - EPT - and AMD Rapid Virtualization Indexing (RVI). Running on these processors, ESX VMkernel will aggressively try to use Large Pages (for reference, look at "Performance Evaluation of Intel EPT Hardware Assist."
So, how does ESX kernel manage zero pages on processors with hardware-assisted MMU?
We have done numerous Memory Overcommitment tests in our POC lab in the last few months, and our tests show that during the Windows boot process, ESX recognizes this zeroing process and doesn’t allocate physical memory to these pages. Since these pages were zeroed out by the guest OS anyway, ESX pools all of them under shared pages (SHRD), and the shared saved (SHDSVD) statistics. These statistics indicate that the memory pages should have been allocated to a specific VM but were not physically allocated as the VM did not need them yet. In other words, these zeroed pages were “virtual” and not physical.
Test on Server without Intel EPT Support
We first run the test on the server with the Intel 5300 series processors without Intel EPT support to show the boot storm: 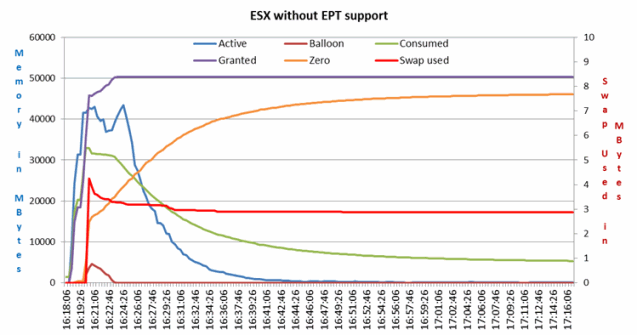 Figure 1 Boot-storm Memory Usage on ESX server without Intel EPT – Extended Page Table
Figure 1 Boot-storm Memory Usage on ESX server without Intel EPT – Extended Page Table
In Figure 1, we can see the 12 VMs start to zero out their memory on power up; these zeroed pages are actually being allocated by ESX. This is evident from the consumed memory statistic shown in green. As the Consumed memory increases rapidly and encroaches toward the 32GB of total physical memory, this forces ESX to reclaim memory using Memory Ballooning and even kernel Swapping.
The memory swap statistic is shown in red and displayed using the 2ndary axis on the right (due to its scale). As TPS starts to share and reclaim the “zeroed pages,” as indicated by the “Zero” memory statistics shown in brown, the Consumed memory gets reduced and so does memory contention.
We can see the memory balloon get deflated to zero in about 4 minutes (just after 16:22:46). But we will also note that it takes about 20 minutes for the “Consumed” memory to go below 10GB, since TPS takes time to scan, share and reclaim memory.
Test On Server with Intel EPT Support
The boot storm memory usage statistics with the Intel Xeon 5500 series processor with hardware-assisted MMU are shown in the following graph: 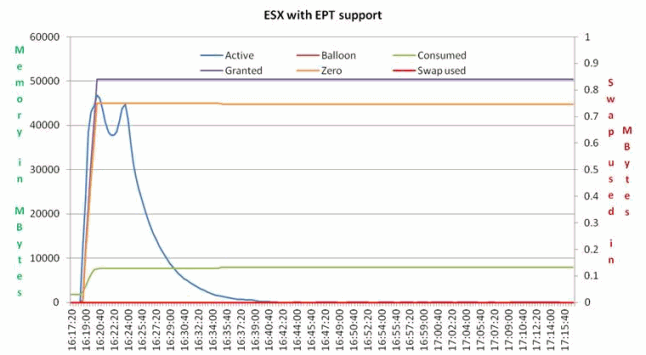 Figure 2 Boot-storm Memory Statistics on ESX Server with Intel EPT
Figure 2 Boot-storm Memory Statistics on ESX Server with Intel EPT
In Figure 2, it is clear that the “zeroed” memory has been recognized by ESX but no physical memory has been allocated. As such, it took very little time to completely power up these 12 VMs and there was no overcommit compared with the first test in Figure 1. There is no Kernel Swapping either.
Conclusions
Based upon our test results, we conclude that:
- Transparent Page Sharing runs on all vSphere 4.x systems with processors that have no hardware-assisted MMU virtualization support.
- On systems with processors that support hardware-assisted MMU virtualization (e.g. Intel EPT), ESX will use large pages and TPS will only kick-in when ESX is under memory pressure.
- ESX will reset physical memory to “zeroed” pages on all vSphere 4.x systems with processors that have no hardware-assisted MMU support.
- On systems with processors that support hardware-assisted MMU virtualization, ESX will recognize the “zeroed” pages but will not allocate physical memory to them. Instead, ESX will pool all of them under shared pages (SHRD), and include them in the shared saved (SHDSVD) statistics.
So, this is great news for applications such as VDI running on newer processors with hardware-assisted MMU. The potential for Memory Overcommitment and the time to power on VMs could be substantially reduced when VDI users are trying to power on their VMs at the beginning of the workshift, for example.
Author: YP Chien, Ph.D. - Kingston Technology